
1. 为什么医学图像分割会关注 Mamba?
医学图像分割(2D/3D)经常同时需要:
- 局部细节:边界、薄结构、小器官(CNN 擅长)
- 全局一致性/长程依赖:器官形态、拓扑、跨切片/跨区域一致(Transformer 擅长)
- 可承受的计算与显存:尤其 3D 体数据,token 数量非常恐怖
Transformer 的自注意力核心瓶颈在于:序列长度 (L) 变大时计算/显存大多是 (O(L^2)) 级别(即使有各种“高效注意力”,也常常要在效果/工程上做取舍)。
Mamba 的核心诉求是:像 RNN 一样线性扩展(随 (L) 线性),同时又具备接近注意力的“内容选择/推理能力”。论文明确提出其目标是以 线性时间规模建模长序列,并用“选择性(selective)状态空间”引入输入相关的选择机制。
2. 状态空间模型 SSM:从直觉到最核心的三组公式
先别被“状态空间”四个字吓到。你可以把 SSM 当作一种“带有连续/离散动力学的 RNN”,它用一个隐藏状态 (h) 来累积历史信息。
2.1 连续时间形式(直觉:动态系统)
论文从经典形式出发(连续系统):
[
\frac{d h(t)}{dt} = A h(t) + B x(t), \qquad y(t) = C h(t)
]
其中:
- (x(t)):输入信号(序列/时间信号)
- (h(t)):隐藏状态(维度通常是 (N))
- (y(t)):输出
- (A):状态转移(决定“记忆衰减/振荡/稳定性”等动力学)
- (B):把输入写入状态
- (C):从状态读出输出
这就是论文的式 (1a)(1b)。
2.2 离散时间形式(更像你熟悉的 RNN)
把时间离散化后(按步 (t=1,2,\dots)):
[
ht = \bar{A} h{t-1} + \bar{B} x_t,\qquad y_t = C h_t
]
这对应论文的式 (2a)(2b)。
💡 一句话直觉:
(\bar{A}) 控制“上一时刻状态留多少”,(\bar{B}) 控制“当前输入写多少”,(C) 控制“读出什么”。
2.3 卷积形式(SSM 还能等价成 1D 卷积)
对 线性时不变(LTI) 的 SSM,输出还可以写成全局卷积:
[
K = (CB,\; CAB,\; CA^2B,\;\dots), \qquad y = x * K
]
这是论文的式 (3a)(3b)。
这件事非常关键,因为:
- 卷积形式让训练时可以并行(像 CNN 一样)
- 递推形式让推理时可以一步一步更新(像 RNN 一样)
3. 传统 SSM 的关键限制:LTI(线性时不变)
SSM 之所以能快,历史上一个重要原因是它们通常被设计为 LTI:参数 ((\Delta, A, B, C)) 在所有时间步都不变,因此可以走高效的卷积/FFT 等计算路径。论文明确指出:此前结构化 SSM 基本都是 LTI,受制于效率约束。
但是 LTI 有一个“天然的短板”:
同一套动力学参数面对所有 token
它很难像注意力那样根据内容做“选择”:该记住谁、该忘掉谁、该跳过哪些噪声 token。
Mamba 论文把这个问题概括成:很多次二次复杂度(或次二次复杂度)的序列模型在离散/信息密集数据(例如文本)上不如注意力,一个关键弱点是缺少高效的输入依赖选择能力。
4. Mamba 的第一核心:Selection 机制(让 SSM 参数“看输入说话”)
Mamba 最关键的一刀:让 SSM 的部分参数变成输入 (x_t) 的函数。论文把它称为 selection mechanism:通过输入去参数化 SSM 参数,使模型能“过滤无关信息,长久记住相关信息”。
4.1 从 S4(传统)到 S6(选择性)
论文用伪代码非常清晰地区分:
- Algorithm 1:SSM(S4):参数时间不变
- Algorithm 2:SSM + Selection(S6):参数随 (t) 变化(输入相关)
Algorithm 2 的核心是:
让 (B_t, C_t, \Delta_t) 由输入生成:
- (B \leftarrow s_B(x))
- (C \leftarrow s_C(x))
- (\Delta \leftarrow \tau\Delta(\text{Parameter} + s\Delta(x)))
并在每个时间步离散化后做 SSM 递推(scan)。
你可以把它理解成:
同一个 SSM 框架
但每个 token 都会“临时决定”自己该写多少进状态、该读出什么、以及这一步的“步长/门控”大小。
4.2 关键图:Selection 在结构上“加了什么”
下面这张图非常推荐你在脑子里记住(来自官方仓库 assets,对应论文图 1 的核心含义):

图 1:选择性状态空间模型:输入 (x_t) 通过 selection mechanism 生成/调制 (B_t, C_t, \Delta_t),并配合硬件友好的 state expansion 设计。。
你可以对照着读:
- (x_t) 经过投影(Project)
- 产生 (B_t, C_t, \Delta_t)
- 再离散化(Discretize)进入递推更新
- 输出 (y_t)
5. 计算挑战:参数随时间变了,卷积路走不通怎么办?
你可能会问:
既然参数 (B_t, C_t, \Delta_t) 每个时间步都不一样,
那不就不能用卷积形式 (y=x*K) 的高效并行了吗?
是的——论文明确指出:时间变化的 SSM 无法走卷积路径,必须用递推(scan)来计算。
但 Mamba 仍然快,靠的是两个思路:
- 数学结构:递推更新是“线性/仿射”的(可以被并行 scan)
- 硬件工程:设计了硬件友好的并行 scan 方案,避免把巨大的 state 展开到慢显存里(HBM),尽量在更快的层级(SRAM/片上)完成融合计算。
🧠 一个非常有用的“简化版”递推形式
把每个通道/每个 state 维度上的更新想成标量递推:[
h_t = at \, h{t-1} + b_t
]其中 (a_t) 来自 (\Delta_t) 与 (A) 的离散化,(b_t) 来自 (B_t x_t)。
这种形式可以用并行 scan(类似前缀和)高效计算。
6. Mamba Block:把“Conv + Selective SSM + Gated MLP”揉成一个可堆叠的 Block
到这里我们已经理解了 Selective SSM(S6)。但在深度网络里,我们还需要一个像 Transformer block 一样可堆叠的结构。
论文的做法是:把典型 SSM 架构(H3 系)与现代网络中常见的 gated MLP 融合成一个统一 block,然后重复堆叠即可(不再需要 attention 或单独的 MLP block)。
6.1 关键图:H3、Gated MLP 与 Mamba 的组合关系
这张图(对应论文 Figure 3 的结构概念)非常适合放在博客里当“总览”:
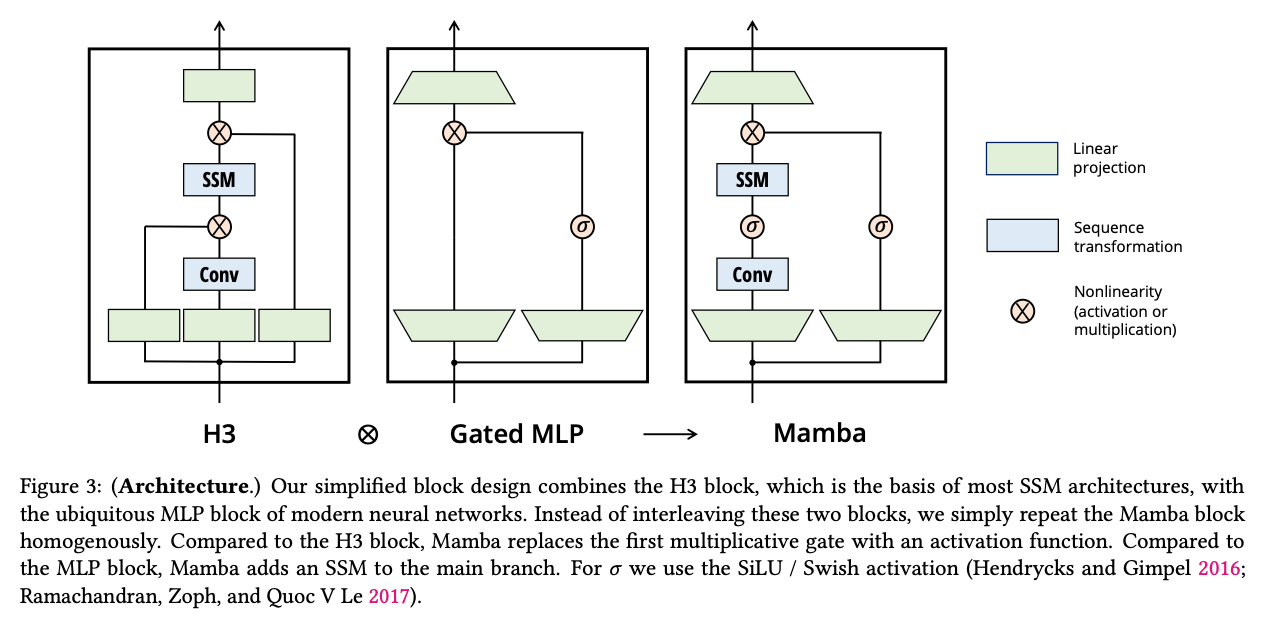
图 2:Mamba block 可以理解为把 H3(Conv+SSM+门控)和 Gated MLP 融合:相对 H3,用激活函数替代第一处乘法门;相对纯 MLP,在主分支加入 SSM。。
✅ 你现在可以用一句话记住 Mamba Block:
“SwiGLU(gated MLP)+ 一个额外的 Conv→SSM 序列通路”。
6.2 Block 内部都在做什么(按数据流拆开讲)
下面我用“实现者视角”拆开一遍(不纠结每个符号的命名,先抓住结构):
假设输入为:
- (x \in \mathbb{R}^{B\times L\times D})(batch, length, dim)
Step 1:维度扩展(Expand)+ 分两路
Mamba block 会把通道维扩展一个因子 (E)(论文实验里常固定 (E=2)),大部分参数都在输入/输出投影里。
你可以写成:
[
[u, v] = x W_{\text{in}}, \quad u,v \in \mathbb{R}^{B\times L\times (E D)}
]
- (u):走 Conv→Selective SSM 的“序列变换”主路
- (v):作为 门控/激活 的辅助路(类似 SwiGLU 的 gate)
Step 2:局部混合(Conv)
在进入 SSM 之前,加一个小窗口的 1D 卷积(通常是 depthwise causal conv,用来补足局部建模)。图 2 里 Conv 就是这个。
直觉:
- SSM 更像“长程记忆/传播”
- 小卷积更像“局部纹理/短程混合”
两者互补。
Step 3:生成选择性参数((\Delta_t, B_t, C_t))
这是 Mamba 的灵魂:从当前 token 的表征里生成选择性参数:
- (B_t = s_B(u_t))
- (C_t = s_C(u_t))
- (\Deltat = \tau\Delta(\text{Parameter} + s_\Delta(u_t)))
对应 Algorithm 2 的核心。
Step 4:Selective SSM(scan)
每个时间步做离散化并递推:
- 先用离散化规则把连续参数变成离散参数
- 再递推更新 (h_t),读出 (y_t)
SSM 的基础离散化(论文给出 ZOH):
[
\bar{A} = e^{\Delta A},\qquad
\bar{B} = (\Delta A)^{-1}(e^{\Delta A}-I)\cdot \Delta B
]
这是论文式 (4)。
然后按式 (2a)(2b) 更新即可。
Step 5:门控(为什么它“像注意力”但不是注意力)
Mamba block 里还有一个关键:gating/activation。
论文给了一个非常重要的连接:当状态维度 (N=1) 等特例下,选择性 SSM 的递推会退化成经典 RNN 门控形式:
[
g_t = \sigma(\text{Linear}(x_t)),\qquad
h_t = (1-gt)h{t-1} + g_t x_t
]
这是论文 Theorem 1 / 式 (5)。
💡 直觉翻译:
- (g_t) 大:强更新,把当前 token 写进记忆(甚至“覆盖”旧状态)
- (g_t) 小:弱更新,主要保留旧记忆,当前 token 更像“噪声”被忽略
这也是为什么 Mamba 的 “selection” 可以被理解成一种更广义、动力学更强的 gating。
Step 6:输出投影 + 残差
最后把 (ED) 投回 (D):
[
\text{out} = x + \text{ProjOut}( \; \text{SSM}(u) \odot \phi(v) \;)
]
其中 (\phi) 常用 SiLU/Swish,使其 gated MLP 对应 SwiGLU 风格。
7. 把 Mamba 当作“医学图像分割的骨干模块”时,你需要知道什么?
这部分只做“基础对接”,不展开视觉专用 scanning/结构变体。
7.1 把图像变成序列:token length 是关键矛盾
二维图像(或三维体数据)进入 Mamba 的最朴素方式:
- patch embedding(Conv/Linear)
- 展平成 token 序列
- 送入一堆 Mamba blocks
例如 2D:
- 图像 (H\times W)
- patch 大小 (P\times P)
- token 数 (L=(H/P)(W/P))
对 3D:
- (H\times W\times Z)
- patch (P\times P\times P)
- (L=(H/P)(W/P)(Z/P))
你马上就能理解 Mamba 的价值点:
当 (L) 很大时,注意力的 (L^2) 会变得非常吃力,而 Mamba 的核心计算随 (L) 线性扩展。
7.2 位置/空间结构:SSM 天生是 1D 序列,你要给它“空间感”
对医学分割,你一般会关心:
- 局部邻域(边界细节)
- 全局空间一致性(器官整体形状)
原始 Mamba 是 序列模型,所以“序列化方式”会强烈影响它学习到的空间关系(比如 raster scan 会把 2D 邻居变成 1D 邻居,距离可能被拉长)。
这一点正是很多视觉 Mamba 变体要解决的问题,但你在写“基础篇”时可以先把它当作:
- “一种比 attention 更省 (L) 的长程 mixer”
- “配合局部卷积补足局部建模”
7.3 你可以直接类比 U-Net:把“Transformer block”换成 “Mamba block”
原论文在音频实验里就明确提到:他们在一个 U-Net backbone(含 pooling、多 stage)里,把原本交替的 S4+MLP blocks 替换成 Mamba blocks。
对医学图像分割,你可以先用同样的“替换思路”建立 baseline:
- Encoder:Conv/patch embed + 下采样 + Mamba blocks
- Bottleneck:更多 Mamba blocks
- Decoder:上采样 + skip connections +(Conv 或 Mamba blocks)
8. 最小可跑示例:用官方 mamba_ssm 先把 Block 跑起来
下面是官方仓库 README 中的最小用法(输入输出同形状):
import torch
from mamba_ssm import Mamba
batch, length, dim = 2, 64, 16
x = torch.randn(batch, length, dim).to("cuda")
model = Mamba(
d_model=dim, # 通道维 D
d_state=16, # 状态维 N(每通道的 state size)
d_conv=4, # 局部卷积宽度
expand=2, # 通道扩展倍数 E
).to("cuda")
y = model(x)
assert y.shape == x.shape